The most commonly-used DTP applications are FrameMaker, Word, Interleaf, QuarkXpress, and PageMaker. Of these, FrameMaker and Word are the most prevalent. With the exception of Word, these formats cannot be directly processed by Translation Memory tools. Filters must be used to convert native DTP files into a Translation Memory-compatible format - usually RTF.
The functions of a filter are:
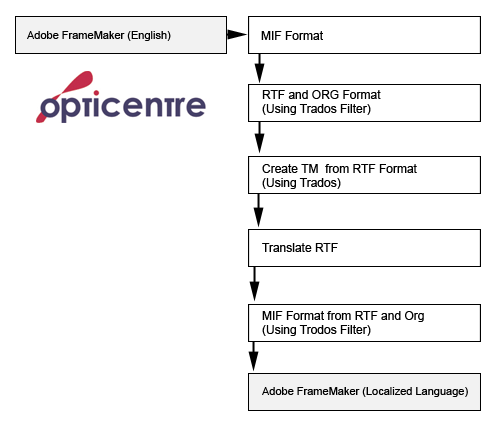
Prior to applying a filter a number of DTP preparation steps must be performed - these steps vary depending on the DTP package, and depending on the particular Translation Memory tool which is being used. For example, if Trados is being used prep for FrameMaker files includes:
These steps are performed in order to minimize the amount of post-translation DTP work which will be required, and also to optimize segmentation during translation. Once these steps have been preformed the Trados FrameMaker filter -S-Tagger for FrameMaker - can be applied. The filter converts the MIF files to an RTF format known as STF. The STF format contains a representation of the style, content, and structure of the original FrameMaker file.
The next step following the application of a filter is Leverage Analysis. The files are loaded into the Translation Memory tool and analyzed against the appropriate TM to establish the scope of translation required. The report generated by the analysis shows the leverage available from the Translation Memory and the word counts for each of the files analyses. The report sub-divides the leverage available into repetitions, 100% matches, high fuzzy matches, low fuzzy matches, and no matches. A project TM can also be extracted which will contain all of the relevant segments for the project. This subset of the main Translation Memory is then included with the translation kit which will be sent to the translators.
 English
English Bulgarian
Bulgarian